
In 2026, the field of enterprise AI changed radically. AI agents are operating 24/7 and more effectively managing thousands of tasks at once as companies are reducing operational costs by 60-80 percent and enhancing customer experiences in quantifiable ways. The competitive advantage? Significant. Here is the reality however: 40 percent of agentic AI projects do not make it to production.
See the fallacy: “Creation of agents is very complicated you have to have a PhD in machine learning. That’s outdated thinking. The contemporary models have liberalized agent development. Basic agents require 2-3 weeks to construct. Production-ready systems? Proper planning and testing could take around eight to twelve weeks.
The statistics speak volumes: 61 percent of the businesses are already developing agents. Those that do fail are not hitting technical walls, they are hitting roadblocks of integration and misreadings of monitoring. Coding prowess is not the difference between success and failure. It is knowledge of the architecture, selection of the appropriate framework, and knowledge of failures of the agents in real life deployments.
The article dissects all that is required to construct production-scale production agents. We will discuss the six main building blocks that every agent needs, compare six possible frameworks that should be considered (between open-source and enterprise-grade), and go through the very process of building an agent, which has eight steps. The breakdown points, the areas that have the majority of deployments failed, are identified during the entire procedure in order to prevent them.
When you are comparing Agentic AI Explained: Multi-agent Systems and the way such systems coordinate multiple agents to be mutually beneficial, you will see those patterns all over this guide with the details of execution.
Core Components of Every AI Agent
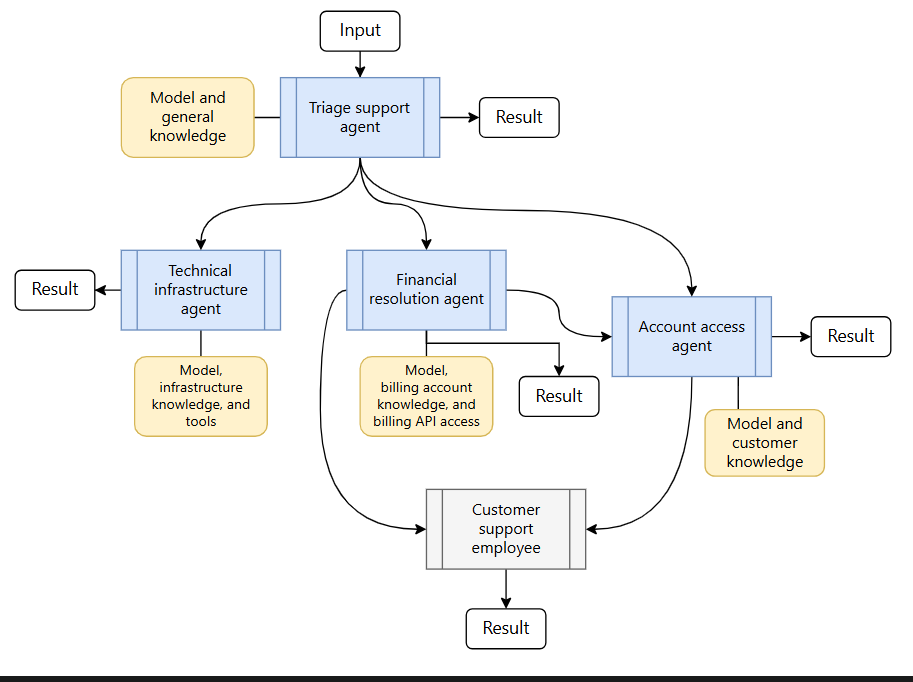
All AI agents, including customer service, refunds, data analysis, etc., are conducted on six key components. Lacking any single component will either cause the agent not to work or to not scale. These 6 pieces cannot be negotiated in the production deployments.
Component 1: LLM Core (The Brain)
The decision-maker of the agent is the Large Language Model. This is the place in which reasoning occurs, in which the agent makes a decision regarding the next step that should be taken, decodes user requests, and produces answers. AG quality directly depends on reliability and accuracy of agents.
Available options:
Best performance is provided on closed-source models:
- GPT-4 is the most justified model of complex workflows (financial approvals, legal reviews, and so on).
- Claude is exceptional in the longer context window and subtle comprehension with excellent rationality.
- Gemini also has a good performance with the low price range, and it will be affordable in terms of deployment.
The control and privacy are offered by open-source models:
- Llama 2 and Mistral make it possible to self-host, leaving the data privacy in full control and long-term expenses.
- Compromise: Worse skills in complicated reasoning topics, and more timely engineering effort.
The choice criterion is really simple: In case the accuracy and the depth of the reasoning are the most important (financial approvals, medical decisions, legal reviews), GPT-4 or Claude are the obvious options. Assuming that privacy or control over costs is of paramount importance, Llama 2 functions, but one should be prepared to spend more time on timely engineering and testing.
The size of the context window is important than most teams know. The GPT-4 with 128000 tokens; Claude has 200000 tokens. Longer context refers to the ability of the agent to remember more history of the conversations and is able to handle some bigger documents without vital information lost.
Fine-tuning decision: The majority of teams are not required to fine-tune their models. Fine-tuning is used when it is dealing with very highly domain specific jargon (Medical terminology, legal terms, industry specific processes) or other workflow patterns. Otherwise, the benefits of prompt engineering are 90 percent with no extra cost.
Component 2: Tool Integration (The Hands)
Integration of tools changes the agents to not answering questions but rather performing tasks. This feature links the agent with external systems, Salesforce, SAP, databases, and custom APIs, and this allows the agent to get data, update records, and take action on its own.
How tool integration works:
- Determine the tools to be used (functions that the agent can use)
- This is done by the use of agent which analyzes the request made by the user and decides on what needs to be done.
- The decision on the tool to employ and creation of the needed parameters is done by agent.
- System calls the tool and reports the results back to the agent.
- The results are used by agent to resume the task or give a reply.
Real-life situation A customer wants a refund. The agent retrieves the details of orders in the database with the help of the checkorder tool, checks the eligibility of the refund according to the company policies, and calls the processrefund tool to provide the credit and update the accounting system.
Definition requirements of the tools:
- Naming of functions: Descriptive names such as getcustomerdata should be used in place of such generic names as fetch.
- Explicit parameter schema: Strengthen data types, parametric requirements (directional, optional), valid set of values.
- Detailed documentation: Author the description of the various tools that the LLM will be able to process to know when and how to utilize each of the tools.
The reliability of the agents is directly related to the quality of the description of the tools. Poorly recorded tools I have used, and the results are predictable like when agents call “deleterecord” when they meant archiverecord” due to the similarity of descriptions recorded or ambiguity.
Component 3: Memory & Context (The Memory)
Memory defines what the agent recalls in the conversations and sessions. In the absence of memory management, the agents forget user preference, they lose track of multi step tasks and can even pose repetitive questions to the user, which causes frustration to the user.
Four types of memory systems:
The current chat session is stored in the conversation memory in verbatim. This offers short-term conversational coherence but dies out easily when engaged in prolonged communication.
Long term memory reads and records past interactions including their facts and preferences in their database. This allows customization between sessions- forgetting that a user likes email-like notifications to SMS messages.
The knowledge base memory also stores company policies, product documentation and frequently asked questions, which is generally supported through semantic search capabilities by using vector databases.
System memory records the state of the current task-where the agent is in process of multi step workflow, and what decisions made, what needs to be done.
The monolithic storage used in early agent deployments was context windows. This causes a kind of pollution of context- agents forget the initial requirements selectively as windows get filled with the information. The hierarchical memory architecture is enacted by modern systems: short- term (recent talk conversational turn), medium-term (compression of summaries) and long-term (key facts and relationships).
The example of smart memory usage will be as follows: The agent retains the last 5 conversation turns to the literal, recalls the relevant facts, along with long-term storage (user prefers email to SMS, user made last order, which was number 12345), and finds the relevant policy documents in the knowledge base. The context window remains slim, yet the agent has all that it requires to make informed decisions.
Component 4: Reasoning & Decision Logic (The Mind)
This constituent dictates the way in which the agent is thinking over problems. Specifically, simple rules based on if-then are usable in simple tasks, whereas complex tasks require the ability of structured reasoning, which is able to deal with ambiguity and multi-step decision-trees.
Common reasoning patterns:
Chain-of-thought reasoning subdivides the problem into the steps. The agent clearly explains its rationale: First, I will check on the status of inventory. I will then check the order history of the customer. Lastly, I will process the return according to policy considerations.
The theory of tree-of-thought reason involves looking at various course of solutions, and choosing the best one. It is successful in making trade-offs decisions in which the agent should compare alternatives.
The reflection reasoning allows the agent to self-correct and examine its output. The agent: Who knows did I miss any edge cases? Is such response correct and exhaustive?
Planning reasoning designs a top plan when performing actions. This usually happens with multi stage workflow in which the agent is required to coordinate various dependent tasks.
Walkthrough of the chain-of-thought example Chain-of-thought example:
User request: “Process a refund for order #12345.”
- Step 1: Load order details with the help of the order tool called get order.
- Step 2: Check eligibility (is an order, has not been refunded, has not been red flagged as a fraud)
- Step 3: Determine the amount refund (Full refund on unopened returns, 80 percent on opened returns depending on the condition of the returns)
- Step 4: invoke process_refund tool with amount calculated.
- Step 5: Find success and inform customer of same through channel of choice.
The agent demonstrates its effort at every stage of work facilitating debugging and gaining the trust of users by transparency.
Component 5: Monitoring & Observability (The Eyes)
You can’t fix what you can’t see. Monitoring shows the time of failure as well as the reasons and the results of the agents and how to enhance it. The teams that are not monitored identify mistakes several weeks later when the users already reported to human services and the level of satisfaction has reduced.
Key metrics to track:
Completion rate is the percentage of work the agent is able to complete. Goal: 85 percent or more on the manufacturing systems.
Error rate is used to monitor the frequency of tool calls or the exceptions the agent makes. Goal: an acceptable performance of less than 5 percent.
Latency is a metric on how long the agent takes to respond to the user query. Goal: More than 10 seconds on simple tasks, more than 60 seconds on multi-step complex tasks.
The use of tokens is directly proportional to the cost of the interaction. Monitor this measure before it explodes.
The frequency of fabrication of information by the agent is used to detect the rate of hallucination. Even the models of high performance such as Claude Sonnet hallucinate 17% of the time meaning that without exception, the agents based on such models are at risk.
Production systems: logging requirements:
- All of the LLCs calls (input prompt, output response, number of tokens, model version).
- All tool invocations (name of which tool, arguments given, output received, time to run, etc.)
- Decision points (“why did the agent make decision A, rather than decision B?
- Partial Internal errors and full stack tracing debugging.
Dashboards must see real-time operations of agents. Some of the most necessary views are active agent sessions, mistakes in recent frequency, rates of completions over time, and cost burn rate. Such tools as Langfuse, LangSmith or even a home-built Prometheus + Grafana can be suitable in this case.
Component 6: Safety & Guardrails (The Conscience)
Rogue agents will ultimately perform catastrophic acts since they will have absolute power. Guardrails are used to avert bad behavior by avoiding its occurrence and they help avoid costly mistakes to the business and the customers as well.
Typical guardrails applications:
Transaction limits limit exposure to risk: Like the maximum refund per transaction (limited to $500), maximum transactions per day (limited to 100) and maximum value per automated approval (limited to 1,000).
Access controls Data access controls provide least-privilege guarantees: Agents are permitted access only to data they require to perform their particular task. None of the agents is granted complete database access.
Escalation policies involve human-response to decisions that present a high risk: Transactions exceeding specified limits, waivering to normal policies, or specifications that are anomalous.
Input validation also prevents any malicious prompts and injection attacks. This prevents the users who may be trying to manipulate the agent to perform illegal acts.
Checking of output after it is presented to the client: No personal identifiable information (PII) transference, no obscene materials, no artificial data introduced as real.
Confidence limits lead to human escalation in cases whereby the confidence of the agent becomes less than specified limits (usually 70 percent in a production system) (Wilhelm et al.).
Example implementation A file request agent initializes the order price. Any orders above 1,000 emission will automatically be checked by humans. The refund request can be ready, and all the additional information can be prepared by the agent, although it cannot be executed without it. This can avoid expensive errors and also leave the workflow efficient on most typical requests.
A study carried out by the Computer Scientists and Artificial Intelligence lab at MIT proves that in spite of the safe systems, failure occurs 1.45 percent of the time during the production deployment. On a massive scale, that would be thousands of possible breaches. Guardrails mitigate this risk–they are not production system optional items.
Popular Agentic AI Frameworks
A large number of agents are developed based on six frameworks: some of them are free and open-source, whilst the others are enterprise-quality, with commercial licenses. They each possess evident advantages and fatal flaws. This is what is really important in decision-making.
Framework 1: LangChain
LangChain is the agent frame business-wide Swiss Army knife. Open-source Python-based and supports almost all the existing LLM and tool ecosystems.
Strengths:
- Very flexible- developers can decide all the behavior of the agent.
- Large community (significant share of 3 rd party tutorials, thousands of GitHub stars in the category)
- Relig integrations with OpenAI, Anthropic, Pinecone, Weaviate and hundreds more.
- Perfect in concept learning and prototyping agent.
Weaknesses:
- Uses custom code everywhere – no graphical interfaces, no low-code options.
- Reduced monitoring and safety layers are turn-key (teams develop themselves).
- The deployment of production demands more tools (LangSmith to monitor, custom orchestration)
Best in: Prototyping new agent concepts, understanding the agent behavior, custom workflows where one has to have complete control over the behavior.
Learning curve: Medium. Python experience required.
Production readiness: ~70%. Teams should incorporate an elaborate tracking, errors management, and scaling infrastructure.
Cost: Free (open-source). Billed separately and paid on a per-use basis.
Framework 2: AutoGen (Microsoft)
This multi agent coordination framework by Microsoft is an open source framework. AutoGen then naturalizes and manages that pattern in case the use case is multidisciplinary, and if the authors can coordinate and communicate among each other.
Strengths:
- Patterns of conversation constructed-in (agents coordinate using built-in dialogues)
- Well-documented and illustrated by the research personnel in Microsoft.
- Role- playing skills (agents respond dynamically to situations to change roles)
- Workflows that have a human-in-the-loop (can ask them to enter data during a task)
Weaknesses:
- Very young (younger than LangChain, less production deployments to get experience)
- Smaller community (1-2 fewer third party content and troubleshooting content)
- Can be costly when there are many agents making calls to LLMs at once.
Best: Multi- agent coordination, collaboration patterns, situations in which agents are required to negotiate or argue about solutions to the problem and then act.
Learning curve: Medium-High. In order to see through patterns of multi-agency, the conceptual sophistication is needed.
Production readiness: ~75%. In better than LangChain orchestration, still requires monitoring infrastructure.
Cost: Free (open-source). Multi-agent conversation patterns may blow up the cost of the API at LLM.
Framework 3: CrewAI
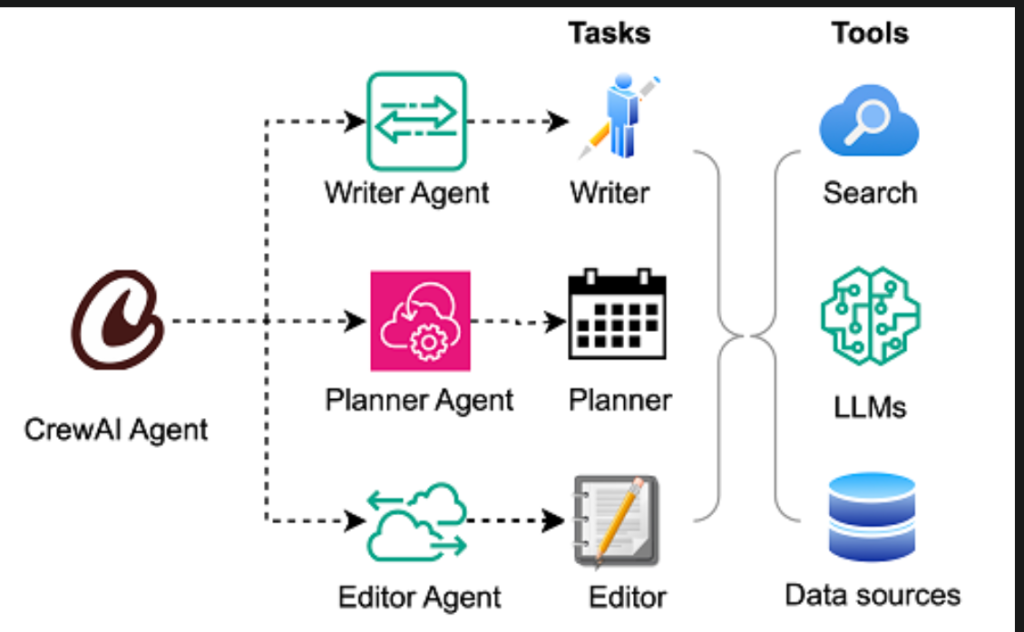
CrewAI is more focused on role orchestration. A group of specialists (researcher, writer, reviewer) is defined by teams, tasks and CrewAI coordinates everything automatically.
Strengths:
- Intuitive role based design (corresponds to the way human beings consider collaborating within the team)
- Good when the workflows are organized, sequential and have distinct dependencies.
- Independent work stream parallelization.
- Good suitability to enterprise applications (especially content generation and research pipelines)
Weaknesses:
- Smaller community (than LangChain) newer framework (less troubleshooting material available)
- Less elastic to non-linear processes or dynamic task scheduling.
- Still catching up on documentation on feature set expansion. Best when: There is a complex workflow with strong roles hierarchy, a content-generation pipeline, research automation need a number of specific perspectives.
Learning curve: Easy. The mental concept of roles is instinctive and natural.
Production readiness: ~80%. Still requires superior orchestration than LangChain although requires powerful observability tools.
Cost: Free (open-source). LLM API is a use based API.
Framework 4: Akka (Enterprise)
Akka is mission critical orchestration written in enterprise style. When scaling on the agents is a priority and high reliability is needed, this is what such an infrastructure is.
Strengths:
- Mission-reliable (safe in financial service and healthcare setting)
- Complete out-of-the-box observability (all decisions are logged and can be traced in order to comply)
- Features of compliance (Database/operating system: HIPAA, SOC 2, GDPR built-in)
- Session replay (watch what agents did on incidents to root cause analysis)
Weaknesses:
- Commercial platform (need significant amount: $5,000-$50000+ per month depending on volume)
- High learning curve (designed with teams in an enterprise environment that has specialized infrastructure engineers)
- Unreasonable when used as a simple or small deployment.
Ideally suited in: Large businesses, systems of business importance (financial services, healthcare), businesses with stringent compliance regulations.
Learning curve: Hard. Needs the knowledge of enterprise infrastructure and no experience in DevOps.
Production readiness: 95%. Designed as a production facility.
Price: $5,000-50,000+/month based on the use of the service in terms of scale of deployment and feature demands.
Framework 5: SuperAGI
SuperAGI is a pre-configured deployment platform with configurable yet low-code agents. Consider it as the no-code deployment of agents, being more speedy than flexible.
Strengths:
- Ready-to-use agents on popular data (customer support, data analysis, document processing).
- define Backup Backups Easy to deploy (connect APIs, set up settings, start to production)
- Out-of-the-box integrations with Salesforce, HubSpot and Microsoft 365.
- Minimum programming (just enough programming to be able to use it as-is)
Weaknesses:
- Less tailorable (difficult to further tailor except by using given templates and designs)
- Readily available few options regarding customization of edge cases or unique requirements.
- The lock-in between vendors (more difficult to jump ship)
Best when: Time to deploy is fast, pre-built use cases are available that fit parameter capabilities, customers do not purport to emphasize seriously managing internal technical resources.
Learning curve: Very Easy. Most of the features are configured with the point-and-click.
Production readiness: ~85%. Good monitoring and support incorporated in platform.
Price: The price ranges between 500-5,000 a month, which will depend on the usage rates and features activated.
Framework 6: Watsonx Orchestrate (IBM)
AI automation workflow platform on enterprise level at IBM. This is what the Fortune 500 companies implement when they require hybrid cloud implementations and a high degree of compliance assurance.
Strengths:
- AI journeys (relates agents to business procedures throughout the enterprise)
- Flexibility in deployment (cloud deployment, on-premise deployment and hybrid deployment)
- Security (ground-up regulated industries compliance)
- Teenage individuality with enterprise programs (SAP, Oracle, legacy databases, mainframes)
Weaknesses:
- Complexity of an enterprise (needs dedicated infrastructure team operated by it)
- High cost (enterprise installations cost the company between 10000 and 100000 dollars per month)
- Difficult to learn (have to be familiar with the IBM ecosystem)
Best suited: Big businesses, hybrid applications (cloud applications are necessary with on-premise requirements), controlled industries with sophisticated compliance requirements.
Production readiness: 95%. Enterprise-level features since the beginning.
Price: Between 10,000 and 100,000 and above monthly on an average enterprise implementation.
Table of Comparison of Frameworks.
| Framework | Best For | Learning Curve | Production Ready | Cost | Type |
|---|---|---|---|---|---|
| LangChain | Prototyping, custom workflows | Medium | ~70% | Free | Open-source |
| AutoGen | Multi-agent coordination | Medium-High | ~75% | Free | Open-source |
| CrewAI | Complex workflows, role hierarchies | Easy | ~80% | Free | Open-source |
| Akka | Mission-critical enterprise | Hard | 95% | $5K–$50K+/mo | Enterprise |
| SuperAGI | Quick deployment, pre-built cases | Very Easy | ~85% | $500–$5K/mo | Platform |
| Watsonx | Enterprise, hybrid cloud | Hard | 95% | $10K–$100K+/mo | Enterprise |
Building Your First Agent – Step by Step
The build process of the production agents takes a period between 45-60 days which is divided into concept, build and deployment. This is the precise eight-stage procedure, which has realistic schedules.
Critical Success Factor:
Step 1: Define the Problem (1-2 days)
These are the basic questions which should be answered specificially before the writing of any code:
What is the particular thing that this agent automates? Example: “Automate the refund of customers less than 500 dollars.
What data is required by it? Examples: Order ID, email to the customer, reason of refund, condition of the return, mode of initial payment.
What decisions must it make? Examples: validate order eligibility, compute the amount of a refund according to the condition of the return, verify fraud warnings, route approval.
What can it NOT do? Example: Verification: Could not refund over 500 without human authorization, could not lift fraud warnings, could not refund an order which was more than 30 days old.
Which are the criteria of success? Example: completion level of 85 percent, the average response level of less than 10 seconds, the error rate of less than 3 percent, customer satisfaction rating of over 4.2/5.
Write these responses in details. Agent projects are murdered by the scope creep. A problem statement is clear to keep the stakeholders focused and the development in tune.
Step 2: Choose Your LLM (1 day)
Factors to consider in the way of making decisions:
Cost: GPT-4 is estimated to be approximately 0.03 USD per 1000 tokens of input and 0.06 USD per 1000 tokens of output. Claude pricing is similar. Charging infrastructure Llama 2 (self-hosted) does not charge API per-token but does have infrastructure costs.
Performance: GPT-4 and Claude are optimal in complicated reasoning. Gemini offers a high-performance at a low cost. Open-source models are implemented in simpler tasks.
Privacy: In the case of sensitive information (healthcare records, financial information), then self-hosted Llama 2 or on-premise deployments would become mandatory, no matter the cost.
Latency: API-based models (GPT-4, Claude) have an average processing time of 2-5 seconds. Self-hosted models may be quicker with appropriate infrastructure yet they demand usage of GPU resources.
Beginner recommendation: Set up GPT-4 or Claude with API. They have proven reliability, are well documented and give time to agent logic rather than infrastructure management.
Example of cost estimation: Assuming that the agent manages 1,000 tasks each day and that the average token usage per task is 2,000(1,000 input and 1,000output) then with GPT-4, one should pay between $60 to 90 per day. Early budgeting and calculation of anticipated volume eludes surprises.
Step 3: Design Your Prompts (2 -3 days).
The operating instructions of the agent are called prompts. Here quality dictates it all accuracy, reliability, behavior and user satisfaction. I discovered that, in my case, 70 percent of the agent failures are caused by vague or unfinished prompts.
There were three categories of prompts needed:
System prompt Role and context of operation: The company is defined by role and context of operation: You will be a customer support code handler who deals with refunds. You want to approve requests and give a refund fairly quickly without violating the policy. You have to make customers understand your thoughts in professional terms with absolute clarity.
Tool description prompts give information on what each of the tools is and when to use it:
getorder: Returns all the order information such as the date of order, items, payment method, and its current status. Whenever you require checking the information on orders before making a refund, then use this tool.
Output format prompts Lays out response format: Return response in JSON format with the following obligatory fields: orderid (string), refundamount (number), status (string: approved/ denied /escalated), reason (string describing why the decision was made).
Example comprehensive system prompt:
You are a money back processing agent. On the occurrence of a customer requesting a refund:
- View order information with the getorder tool with the given order ID.
- Confirm eligibility (within 30 days, has not been refunded, no fraud declaration)
- Compute refund (full refund upon returning together as a non consumed item, 80 percent of original amount upon returning after consumption depending on the condition of the item)
- In case of refund, more than 500 dollars or any validation is not successful, go to human approval with explanation.
- Otherwise process using process-refund tool and ensure that customer confirmed. Always justify yourself in an open way so as to gain customer confidence. When you are not confident in one step, scale up instead of making a hunch.
Set aside considerable time in timely design. Test variations. Which prompts result in the most accurate results.
Step 4: Interaction with Tools and APIs (3-5 days)
It is here that the agent acquires its hands the power to do things other than talk. Relate it to all the systems it has to relate.
For each system integration:
Get permissions: API key artifacts, OAuth access token artifacts, connection-string database access keys, service account permissions.
Manual test calls: Enables check of endpoints prior to being included into the agent. Check responses with the help of such tools as Postman or curl.
Introduce error handling: Specify what to do in each failure mode downof API downof API time outof API when rate limit reachedof API with malformed response of API authentication failed.
Request rate limits: Add exponential backoff logic, queue requests (possibly, with a request queue) and count usage by quota.
The majority of frameworks ( LangChain, CrewAI, AutoGen ) have SDKs of tools that make integration easier. Define tools based on their schema, validate tools on an individual basis and finally binds into the agent orchestration logic.
In accessing systems having multi-agent coordination patterns, provide all the agents with the right level of access and effective coordination plans to prevent any conflicts.
Step 5: Implement Orchestration Logic (2–3 days)
Orchestration to- decide: Gamble to have tasks fired in series or parallel? At what point does the agent wait till human input is provided? Failures and retries? What is its approach to it?
Two primary patterns:
Step by step orchestration Each step waits until the old step finishes. Uncomplicated, predictable, less complicated to debug, and slow on complicated processes.
Parallel orchestration Multitasking or multiple tasks run concurrently. Least amount of time, but needs merge logic and conflict resolution to get results.
The example of the refund workflow (in a sequential manner):
- Get order information within database.
- ERG Test Eligibility-policy rules.
- Computation of amount of refund depending on the condition of the returns.
- Refund of processes by means of payment system.
- Send success notification to customer through email.
The steps are interdependent with the output of the previous step and sequential orchestration is the obvious choice. In case there were independent checks (fraud detection and inventory check) in the subject workflow, they could be run at the same time to be faster.
Step 6: Add Monitoring (1-2 days)
Test the agent then put into production. Being seen at the beginning malevolently forestalls disasters and allows continuous improvement.
Critical metrics to track:
- Percentage of tasks completed successfully
- Error rate versus applicable type of error (in what ways do we tend to fail the most)
- Mean delay of tasks (task duration)
- Use of tokens and costs involved (monitor expenditure to ensure it does not run out of control).
- The rate of escalation (frequency of human assistance of the agent)
Logging requirements:
- All the invocations of the LLM with complete promotion and answer.
- Each parameter and result of tools.
- Anywhere there is a decision point that has a trail of reasoning.
- Full stack traces and the error logs.
Dashboard essentials:
Live monitoring of agent stamping, as well as the occurrences of failure in the most recent session with frequency curve and completion rate curve over time, the costs burned per session, and anomalies triggered alerts.
Primer Tools such as Langfuse, LangSmith or a self-created system of Prometheus + Grafana are all viable. Select one and set it up appropriately and alerts on error spikes or cost overruns.
Step 7: Test Extensively (5–7 days)
The process of testing AI agents is different compared to the process of testing an ordinary program. Deterministic logic is not tested by a team but probabilistic behavior. I have observed that this takes a different attitude and approach.
Test categories required:
Unit test: Tools tested individually are functioning (i.e. mocked LLM responses are used to test tool integration).
Integration tests: Complete end to end workflows with actual LLM calls.
Edge case Tests: POisonous data, unresponsive data, failures of the API, slowness tests.
Load tests: One hundred requests at once: Does the system cope? 1,000? Where does it break?
Manual tests: Human beings connect to the agent and alert them of problems that are not found in automated tests.
Assemble a test suite of common case and edge case scenarios (real world) of 50-100 cases. Run them repeatedly. Track pass rates. Fix failures. Keep on iterating, till the pass rate is above 85%.
Assessment is a resource-consuming process. It is an expensive test cycle (Calls to the API of LLM are not free). Depending on the size of a test set and model used, budget may range between $500 and $2,000 on full testing.
Step 8: Deploy to Production (1–2 days)
Deployment does not mean switching a switch. It is a gradual implementation under safety net and roll back plan.
Deployment checklist:
Certification: Infrastructure (servers, databases, API keys, secrets management) made.
Monitoring active: Dashboards live activated, on call rotation set, alerts set.
Human supervision: The first 100 tasks are supervised by a person to identify the problems that automated monitoring is unable to detect.
Rollback plan: What happens in case everything is wrong? Pre-launch test The test Super Procedure
Finely tuned step by step: 5 percent of traffic at once, watch 24 hours, 25 percent, watch, 50, watch and 100.
Shadow mode works quite well: Agent has to run in parallel with current systems. Compare outputs. Routing real traffic before fixing discrepancies. This captures problems without affecting the customers.
Complete timeline outline: 2-3 weeks to create basic level functional agent, 8-12 weeks to create delivery ready system with enough testing, monitoring and refinement.
Final Thoughts
It is no longer so complicated to have AI agents built in 2026 as the myth would imply. The frameworks are in place, the models are time tested and the deployment patterns have been tested in thousands of production deployments. The success or failure of teams that can achieve 40 percent failure rate boils down to three factors, namely: definite scoping, full monitoring, and realistic expectations.
Start small. Design a single agent that addresses a single well defined problem. Have the reliable working of off guardrailled and monitored. Then scale. Nonetheless, do not even think of trying to automate whole business processes on the first day, that is where projects fail on their complexity.
The models addressed: LangChain, AutoGen, CrewAI, and the enterprise options, all are effective in the target situation. Select on the basis of team competencies and need and not the hype of the marketing. In the case of prototyping: LangChain or CrewAI. In case of reliability in enterprise: Watsonx or Akka. To be implemented quickly: SuperAGI.
The 60-80% cost cutting firms are registering? Real and measurable. The 24/7 operating with
out breaks? Occurring throughout industries. The competitive advantage? Important to mover takers. However, none of them can be useful, in case teams neglect the essentials: right architecture, full monitoring, strict governance, and realistic scoping.
There are 6 key components, and you should begin with them. Choose a suitable framework. The eight step build process should be performed strictly. Implement with proliferation and magistration. And bear in mind–it is magic agents operate, and not magic. Manage them as any other system in the production: in an engineering discipline, operational control, and constant improvement.
I’m software engineer and tech writer with a passion for digital marketing. Combining technical expertise with marketing insights, I write engaging content on topics like Technology, AI, and digital strategies. With hands-on experience in coding and marketing.


