
Last updated on January 10th, 2026 at 02:29 pm
I would have burned a hole in the cloud credits with GPUs in less than three weeks, but then somebody went on to tell me TPUs could be cheaper. This discussion is what put me down a Rabbit hole of AI hardware specifications, benchmarks and acronyms that all sound alike. TPU, NPU, GPU but what is the real difference and what one do you actually require?
This is what I discovered after trying out various combinations, reading a lot too many whitepapers and asking people who actually run such things in large-scale? It doesn’t matter whether you are a student who wants to build your first model, a developer selecting the hardware to build something, or even somebody who is simply interested in how AI actually works: this has down-cut the difference in real-world use without the marketing hype.

The GPU: The Workhorse of AI Still.
What Makes GPUs Special for Machine Learning
The initial purpose of GPUs was card renderer – image whether video games or 3D animation. However, it happens that the same parallel processing capabilities that enable explosions to look real also exist that just happen to be excellently suited to do the matrix math of neural networks.
My consumer gaming card was an RTX 4090, on which I have undertaken a few other models on my hobby projects. It is a beast, the thing has 24GB of VRAM, which is too large to run models of decent size on the computer. The H100 is the data center variant ( NVIDIA H100 ). It has 80GB of HBM (high-bandwidth memory) and is capable of approximately 3.5 petaFLOPS of peak compute.
The aspect that I love about GPUs is that it is versatile. There is no single structure or form of workload. PyTorch, TensorFlow, JAX, they are all working. Training, emotionalizing, mixing-up parts of the classic computing? No problem. The Cloud AI Processors the ecosystem is developed enough as you can spin up the GPU instances in a few minutes.
The Real-World Performance Numbers .
Now, allow me to mention some real figures. The H100 draws approximately 700W under full load and provides an approximate of 1,500 TFLOPS (teraFLOPS or trillion floating point operations per second) of throughput. Single pass inference latency? Typically 50-100 milliseconds, with your size of model and your batch settings.
The RTX 5090, as a consumer card, is in the middle ground, neither 5090 nor its competitors have the power the enterprise-level card that the businesses are running. I have observed that these handle models with up to 20-30 billion parameters and thru some memory management tricks such as gradient checkpointing.
Where GPUs Fall Short
The trick is the following: GPUs are energy intensive and costly. That H100 I mentioned? It will cost you more than 40,000/unit as well as it will require serious cooling apparatus. I actually witnessed my electricity bill in my home installation skyrocket as I was carrying out experiments, 24/7.
When doing pure inference workloads, that is, you are not training but just running predictions then GPUs can seem overkill. You are paying to be flexible when you do not need it, and the complexity in the structure of the architecture implies that you are not always at peak efficiency.
Batch size is also important, small batches will have idle functionality of the GPU due to the launch overhead and synch delays.
TPU: The Deep Learning Engine of Google.
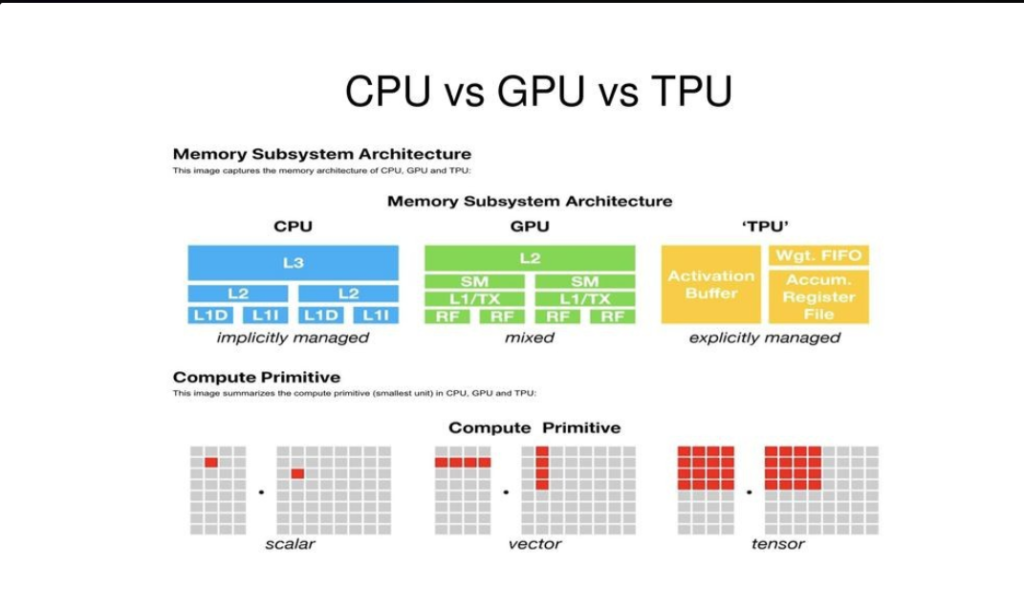
Understanding the TPU Architecture
TPUs are the solution to the question: what would Google do in case it created chips that were optimized to perform tensors? In contrast to GPUs which were developed out of graphics cards, TPUs were developed independently and optimized to perform a single operation: the matrix multiplications of most neural network operations.
I initially tried using Cloud AI Processors such as TPUs when I would need to train a bigger language model and the cost of using GPUs was becoming absurd. TPU v5 and the more recent Ironwood (v7), which comes out in 2025, uses what is termed a systolic array, or, in other words, a 256×256 grid of arithmetic logic units (ALUs), which are capable of running hundreds of thousands of operations per cycle.
Ironwood generation is a 192GB of HBM3e memory with 4.6 petaFLOPS peak compute. The most notable aspect was that it was very energy-efficient approximately 54 TOPS/watt, 2-3 times more efficient in comparison to the competing GPUs.
TPU Performance in Practice.
It is here that should be interesting. TPUs are good with statical, dense tensors – the staples of most deep learning. In one case when I transferred a TensorFlow training job to TPU, I experienced the cost reduction by almost 40 percent and achieved similar performance. Its power consumption is approximately 150W compared to the H100 which is 700W.
However, latency is more than GPUs with single inferences, typically 100-200ms. TPUs are not response time based, they are throughput based. That is all right in case you are handling thousands of requests at a time in batches. In real-time applications with each millisecond being important? Not ideal.
With that 192GB HBM3e memory bandwidth on Ironwood is 110 TB/s. The chip to chip connection is 1.2TPS bidirectional, allowing you to scale thousands of chip when you really require serious power.
The TensorFlow Lock-In Problem.
I was made to find this the hard way: TPUs would highly like you to use TensorFlow. Experimental support of PyTorch (as part of a joint Google-Meta effort known as TorchTPU) is still emerging. Certainly, some friction will be felt in case your codebase is built on PyTorch or JAX.
There is also the learning curve of the XLA compiler that codes TPUs. It is not as easy to debug as it is with Nsight applications of NVIDIA. It was like learning a new dialect of the same language to a person who had experience in GPU development.
In addition, TPUs are available only in Google Cloud. No option on premises, no purchasing your own hardware. The cloud-only model does have its advantages and disadvantages – it is cheaper in the short run, but you are at the mercy of Google and its pricing.
NPU: AI at the Edge
Why NPUs Exist
The specialist of the group is that of the NPUs. As GPUs and TPUs compete against each other in data centers, NPUs address a whole different issue: the implementation of AI in a device with limited resources (power and compactness).
I tried the following one when creating an Android application that required image recognition on the device: Qualcomm Hexagon NPU in Snapdragon 8 Elite, MediaTek APU in Dimensity and even Apple Neural engine are all created to do one thing, and that is to provide efficient inference at low battery cost.
Such chips normally use 1-5 watts – at times down to 2 milliwatts in cases of permanent operation. However, this is several hundreds of watts compared to a GPU, and that is why your phone can run face recognition all day without dying.
The Performance Trade-offs
Mobile implementations are at 10-50 TFLOPS performance. Far fewer than 5 chips in a data center, but can be lower latency and inference times of 5-20ms, and lower values with optimized models. This is important to real-time users such as AR filters or voice assistants.
The size of memory is very small, normally less than 1GB as embedded in the chip. It implies that you are using extremely compressed models. I needed to quantize and INT8 or 8-bit integers, rather than 32-bit floats, the weights, and knowledge distillation to reduce the size of the usable model to 100MB or more.
The ecosystem of Edge Computing Processors is not limited to mobile NPUs, but also has other specific IoT devices. In October 2025, Google unveiled a new Coral NPU called Coral NPU which reportedly delivers 512+ GOPS (billion operations per second) with only a few milliwatts of power. Ethos-U85 by ARM is aimed at the same applications.
NPU Limitations You Must Learn.
NPUs only do inference. You implement on GPU or TPU, and then put the compressed model on NPU. That process is complicated – it requires a complete dev pipeline of quantization, validation, and testing of the compression stages.
There is fragmented support of frames. TensorFlow Lite and ONNX runtime are functional, but for example, developer-specific toolchains. On-betterment debugging pains Death fought five hours figuring out the reason accuracy went down 5 percent after the quantization.
Use cases are narrow too. Vision models, audio processing and lightweight NLP are alright. Something that must have huge context windows Views or dynamic computation? Forget it. NPUs are processing simple predictable inference patterns.
Emerging Alternatives Beyond the Big Three
Custom Operations FPGAs.
FPGAs allow you to implement just-in-time hardware logic of certain operations. I have witnessed these used in research laboratories to do bizarre model architectures not well expressed on GPUs or TPUs. Their flexibility is amazing, and they need significant hardware expertise to be programmed.
Custom ASICs Take on NVIDIA
The construction of their own AI chips (MTIA) by Meta, Amazon with Trainium and Inferentia and TPUs, which are technically ASICs (Application-Specific Integrated Circuits) by Google too. These businesses are attempting to decrease the reliance on NVIDIA by creating chips that best fit their specific applications.
This LPU (Language Processing Unit) by Groq is something that has attracted my attention in the recent past. It is created with the purpose of inference with an architecture of a programmable assembly line that is 10X lower latency than GPUs on certain tasks. In deterministic, ultra-low-latency inference, they reached a valuation of $6.9 billion in the year 2025.
Photonic Chips: The Future Perhaps.
Photonic computing is computed by light as opposed to electricity. Hypothetically it provides close to zero heat emission and higher speeds. Business firms such as Ayar Labs are progressing in this but is not commercially viable yet thus reach 3-5 years which is most likely 2028-2030.
The working scale of photonic chips would render energy costs insignificant, and in case it succeeds, would fundamentally transform the economics of artificial intelligence. However, that is a big IF, I am not in a position to keep waiting.
The Comparison Table: Real Numbers.
That is what counts when selecting hardware:
| Feature | GPU (H100) | TPU (v5/Ironwood) | NPU (Mobile) |
|---|---|---|---|
| Power | 700W | 150W | 1-5W |
| Memory | 80GB HBM | 192GB HBM3e | <1GB on-chip |
| Latency | 50-100ms | 100-200ms | 5-20ms |
| Throughput | 1500 TFLOPS | 1000+ TFLOPS | 10-50 TFLOPS |
| Use Case | Training, inference | Cloud training/inference | Edge inference |
| Cost | $15K-40K+ | Cloud pricing (pay-per-use) | Integrated in SoC |
Understanding the Metrics
TFLOPS is a measure of regular floating-point mathematical performance, higher values are better in training. TOPS (Tensor Operations Per Second) is identical but authorized to tensor math. TOPS is more important than the conventional FLOPS to the modern AI workloads.
Latency is your turnaround time – important to real time applications such as chatbots or autonomous vehicles. Throughput refers to the amount of requests that you can process when you batch them. high throughput, high latency systems are effective with off line, batch jobs. When users are waiting then it is required to have low-latency systems.
Which Hardware Should You Actually Use?

For Large-Scale Training
When models are trained that have more than 100 billion parameters, TPUs would be cost-efficient at 4-10X compared to GPUs, primarily because of its energy efficiency and cloud pricing. The efficiency gains along with the power and cooling cost reductions found in the research were 2-3X and 30-50%.
However, the trick is this: you will need TPU only when you will be devoted to TensorFlow and Google cloud. Otherwise, it is not worth the friction.
Use GPUs when you require a flexible framework or you are in the research safeguard of unstable requirements.
For Real-Time Inference
Invoke perform Mobile NPU processors On edge devices when privacy (data is never transmitted over a network) or low latency (no round trip over a network) or just you are developing on mobile/IoT.
To run inference at scale with clouds, smaller GPUs such as the A10 or L40 should be used and batching aggressiveness should be used. They compare better than H100s on workloads that are inference only.
Groq has LPUs that are specialized to provide deterministic, ultra-low-latency chatbots or real-time systems.
For Mobile and IoT
Architecture Use the built in NPUs in recent mobile SoCs. Snapdragon 8 Elite, Dimensity 9300+ or even the Neural Engine of Apple are all good. Your model must be less than 100MB, must be filled to INT8 and must be pruned by 30 to 50-percent.
The major wins in this case are privacy and battery life. The on-device processing makes sensitive data remain on the device and quantized models on NPU, only incur an approximate battery drain of 5 percent as compared to a baseline.
Practical Tips I Wish I’d Known Earlier
Start with Quantization
Quantization is an advantage of every accelerator. INT8 accuracy reduces memory usage by 75 and throughput 2-4X with a small (typically less than 1 percent) accuracy decrease (typically, vision models). This is what I should have done at the very beginning rather than struggling with issues of memory.
Select Your Hardware Match Batch Size.
Large batches are the favorite of GPUs – it recovers the launch overhead. TPUs too. However, when doing real time inference, small batches are inevitable hence underutilizing GPUs. This is where NPUs or special inference chips would be more reasonable.
Don’t Ignore Total Cost
A 40k GPU is costly compared to the price of power (700w constant) etc. Cloud TPUs do not charge upfront fees but charge racks an ongoing fee. Crunch the real math of your assignment prior to signing a contract.
FAQs.
Are TPUs Always Faster Than GPUs?
No. TPUs scale faster with inhabitants of TensorFlow-specific competitions, typically full 2-4X faster when educating huge models. However, GPUs can best perform with dynamic workloads, sparse operation or in non-templates Frameworks like TensorFlow. GPUs are better in batch throughput and TPUs in the cost at scale inference.
Can I Run PyTorch on TPU?
Traditionally, no TPU was other than TensorFlow. TorchTPU initiative at Google and Meta (2025) is altering this, though the support of PyTorch remains a second-tier one. And, in case you are much invested in PyTorch, then you will be safer using GPUs.
What About Apple’s Neural Engine?
The Neural Engine of Apple is more or less an NPU that is optimized to operate on iOS/macOS. It works well in-app inference on the machine, yet it is entirely restricted to the Apple ecosystem. You get access to it with Core ML, but it is not being run in isolation.
Do I Need to Understand Hardware Architecture?
Half way, not profoundly, but the rudiments have their use. Knowing why TPUs like to use statical shapes or why NPUs like quantization will save you the time spent in debugging. You don’t necessarily have to create chips, but the strength of chips is known so that you do not have to make a matching that is expensive.
Final Thoughts: Specialization Wins
Days when (GPUs) are through all have ended. By 2025, specialization has been broken down: the TPUs will be used across large pieces of the cloud, more power efficient; NPUs will be used at the edge, operating on milliwatts of power and maximizing always-on use cases; and developing low-fourth milliwatts alternatives such as LPUs.
In the opinion of most users entering the field, here is my suggestion: Use GPUs when you need to go flexible, and you are still learning what to do. For current applications MoyneRANGEFO chose to move to TPUs once you have settled on TensorFlow and have to optimize scale. Devices to be sent to NPUs and are mobile or IoT products that are sensitive to power.
It is the ability to match accelerator to the workload. Do not spend too much to pay a capability that you are not going to require but neither should you cripple your project by equipping it with hardware that is not appropriate to support that capability either. It was a lesson I had to learn by trial and error, to your good fortune without some of these costly errors.
Read:
Complete Guide to Semiconductor Chipsets: Types, Architecture & Applications
Mobile Chipsets Explained: Snapdragon vs MediaTek vs Apple Silicon
Chipset Architecture Explained: From Monolithic to Chiplet Design
Computer Processor Architecture: Intel vs AMD vs Apple (2025-2026)
I’m software engineer and tech writer with a passion for digital marketing. Combining technical expertise with marketing insights, I write engaging content on topics like Technology, AI, and digital strategies. With hands-on experience in coding and marketing.


